Odd one here. First I will preface. I have had a miserable experience getting this product setup. Online and local controller problems yesterday had my network down for hours as the switch, router or controller went into recovery mode.
I am passed that after logging into the router and adopting locally after the app failed me.
Moving on; the stack is:
Route10
S8 Poe
Alta local controller
2x AP6 Pros
So, after wrangling it last night I was happy to go to bed around 2am thinking I had a perfectly working network. LAN changed to 10./16 starting at .50. All devices show in the control panel, all stack devices assigned statically.
I have the STRANGEST problem though. Wife is working and at 8:06am she says the internet isnt working. She managed to connect through her VPN and work like that wired in. However, no local wifi devices or other hard wired machines like desktop could.
I rebooted the router and everything came back up. This was around 9am. Throughout the day everything has been working fine. No complaints. I decide to go out and grab some things and she messages me again. A little after 2pm the internet stopped working.
I am close so I come back home and SSH in. I am not the most familiar with openwrt, I have more experience with opnsense, juniper, sophos. I check /var/log/messages I personally dont see anything out of the ordinary.
So before rebooting I decide to check from the device itself. I ping 8.8.8.8 works fine. Must be a DNS issue, I ping google, comes back totally fine! At this point she is getting a little antsy so I reboot the router. Everything starts working immediately. I do some quick match and it seems that around the 5 hour mark something stop working, but no process kills or oom messages are in the log, unless openwrt keeps these elsewhere?
I have attached the log while it wasnt working, and attached the log after the reboot. I am able to provide anything else you may need, but would love some assistance because I am at a loss.
It should be noted EVERY single device went through FW recovery several times yesterday while I was trying to adopt. Following the instructions Alta provides. At this time everything is upto date, even the controller on 1.0u.
You have any devices set with hard coded static IPs from your previous network? Only issue I ran into was a TV that I had manual set to static IP for Control4 purposes and was creating a conflict when I switched from Unifi.
Maybe a NAT or firewall issue on the Route10? I’d also be interested if you plug a client directly into Route10 does that device also experience the issue when in the broken state?
I would also tcpdump on the WAN interface (if this is possible on Route10, I don’t have one) in the working and broken state to see if traffic is being NATed and sent out to ISP.
Thanks for reaching out! I do actually; but the range is higher than my current equipment. I dont have anything reserved under .15 which is what I leave for my network gear.
I have two switches connected. 1 10g switch to the route10 10g lan via SFP+. The other is the S8 POE and that is connected to one of LAN ports on the route 10. Devices from both switches fail to reach out when issue happens. They can reach each other, and the route10 can reach them, but none can reach the WAN but the route10 itself (via SSH).
Certainly! If I can assist in anyway I’d be more than happy too.
Fair enough. My first thought was that you had a rogue DHCP server because half the Alta devices had 10.0.0.x addresses and the other half had like 10.0.127.x addresses and there were no other VLANs. Ok, refocusing
Here is the issue with local controllers, pretty good odds that if you lose connection, so do I. I’ve lost access as well so feel free to get back up and running.
I made one change and one change only, I shortened your DHCP lease time to 300 seconds. Reason being if I change the subnet from that /16 there would be clients who don’t get the memo until they go to renew their DHCP lease. Default is 24 hour lease time, DHCP renews at the halfway point, so I didn’t really want to knock your clients offline for up to 12 hours nor did I want to tell you that you have to reboot your entire network (again).
So it was simply a pre-emptive setting. I was running a packet capture on DHCP to confirm no rogue DHCP but you’ve confirmed it (apologies, it’s difficult to discern one’s technical abilities from brief bits of text so I have to feel it out a bit).
The first thing I want to do is limit that subnet to something more reasonable, haven’t really found a root cause just yet.
I went ahead and did some digging while I was down.
First, All devices in the house went down while I was getting coffee. TV stopped streaming Sonos got mad phone and PCs stopped connecting to outside things. Websites, Chat clients, emails you name it.
At all times the machines said they were online. What I mean is, The connection icons didnt get crossed out on mac, the connection icon didnt turn into a globe with a line through it on windows etc.
When running some tests though, I could ping out from my desktop and resolve DNS. I tried a few sites:
PS C:\Users\solar> ping 10.0.0.1
Pinging 10.0.0.1 with 32 bytes of data:
Reply from 10.0.0.1: bytes=32 time<1ms TTL=64
Reply from 10.0.0.1: bytes=32 time<1ms TTL=64
Reply from 10.0.0.1: bytes=32 time<1ms TTL=64
Reply from 10.0.0.1: bytes=32 time<1ms TTL=64
Ping statistics for 10.0.0.1:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 0ms, Average = 0ms
PS C:\Users\solar> ^C
PS C:\Users\solar> ping 10.0.0.19
Pinging 10.0.0.19 with 32 bytes of data:
Reply from 10.0.0.19: bytes=32 time<1ms TTL=64
Reply from 10.0.0.19: bytes=32 time<1ms TTL=64
Reply from 10.0.0.19: bytes=32 time<1ms TTL=64
Ping statistics for 10.0.0.19:
Packets: Sent = 3, Received = 3, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 0ms, Average = 0ms
Control-C
PS C:\Users\solar> ping 8.8.8.8
Pinging 8.8.8.8 with 32 bytes of data:
Reply from 8.8.8.8: bytes=32 time=6ms TTL=59
Reply from 8.8.8.8: bytes=32 time=6ms TTL=59
Reply from 8.8.8.8: bytes=32 time=6ms TTL=59
Reply from 8.8.8.8: bytes=32 time=6ms TTL=59
Ping statistics for 8.8.8.8:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 6ms, Maximum = 6ms, Average = 6ms
PS C:\Users\solar> ^C
PS C:\Users\solar> ping google.com
Pinging google.com [74.125.138.138] with 32 bytes of data:
Reply from 74.125.138.138: bytes=32 time=6ms TTL=59
Reply from 74.125.138.138: bytes=32 time=7ms TTL=59
Reply from 74.125.138.138: bytes=32 time=6ms TTL=59
Reply from 74.125.138.138: bytes=32 time=6ms TTL=59
Ping statistics for 74.125.138.138:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 6ms, Maximum = 7ms, Average = 6ms
I found taht odd since virtually everything that connects to wan in the house stopped working. I figured packetloss maybe, but I dont want to poison your thought process.
I then took a peek at the connections on thee router itself. Still showed the interfaces up. Looks like in this case eth4 is my ISP.
root@Route10:~# opkg install tcpdump
Package tcpdump (4.9.3-3) installed in root is up to date.
root@Route10:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group defaul t qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: miireg: <> mtu 0 qdisc noop state DOWN group default qlen 1000
link/netrom
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq master br-lan state UP group default qlen 1000
link/ether bc:b9:23:81:3d:2c brd ff:ff:ff:ff:ff:ff
4: eth1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq master br-lan sta te DOWN group default qlen 1000
link/ether be:b9:23:82:3d:2c brd ff:ff:ff:ff:ff:ff
5: eth2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq master br-lan sta te DOWN group default qlen 1000
link/ether be:b9:23:83:3d:2c brd ff:ff:ff:ff:ff:ff
6: eth3: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000
link/ether bc:b9:23:81:3d:2d brd ff:ff:ff:ff:ff:ff
7: eth4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group defa ult qlen 1000
link/ether bc:b9:23:81:3d:2e brd ff:ff:ff:ff:ff:ff
inet 136.red.act.ed/20 brd 136.53.191.255 scope global eth4
valid_lft forever preferred_lft forever
inet6 fe80::beb9:23ff:fe81:3d2e/64 scope link
valid_lft forever preferred_lft forever
8: eth5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq master br-lan state UP group default qlen 1000
link/ether be:b9:23:84:3d:2c brd ff:ff:ff:ff:ff:ff
9: ip6tnl0@NONE: <NOARP> mtu 1452 qdisc noop state DOWN group default qlen 1000
link/tunnel6 :: brd ::
10: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 2e:8f:cc:f0:b5:8f brd ff:ff:ff:ff:ff:ff
11: gre0@NONE: <NOARP> mtu 1476 qdisc noop state DOWN group default qlen 1000
link/gre 0.0.0.0 brd 0.0.0.0
12: gretap0@NONE: <BROADCAST,MULTICAST> mtu 1462 qdisc noop state DOWN group def ault qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
13: erspan0@NONE: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN group def ault qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
14: ip6gre0@NONE: <NOARP> mtu 1448 qdisc noop state DOWN group default qlen 1000
link/gre6 :: brd ::
15: bond0: <BROADCAST,MULTICAST,MASTER> mtu 1500 qdisc noop state DOWN group def ault qlen 1000
link/ether f2:bf:10:41:91:75 brd ff:ff:ff:ff:ff:ff
16: br-lan: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP gr oup default qlen 1000
link/ether bc:b9:23:81:3d:2c brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/16 brd 10.0.255.255 scope global br-lan
valid_lft forever preferred_lft forever
inet6 fe80::beb9:23ff:fe81:3d2c/64 scope link
valid_lft forever preferred_lft forever
root@Route10:~# tcpdump -i eth4 -ne -w /tmp/dump.pcap
tcpdump: listening on eth4, link-type EN10MB (Ethernet), capture size 262144 bytes
With that I began a tcpdump for you. The following IP is the local machine I used to test.
Thank you for the detailed troubleshooting steps and the TCP dump.
For the record, I edited your post to block out your public IP as a cautionary measure. Us admins can see edit history so I can still see it if necessary, but yeah, I don’t want to be the cause of a DDOS attack or some crazy stuff because the www actually means “wild wild west”
Given the circumstances, the ping results are quite perplexing. I made a minor change to the configuration, but I’m not telling until tomorrow haha. You can find it if you poke around, but I just want to see if there’s another failure in approximately 3.5 hours. It’s a benign change on paper, but given the circumstances, we’re definitely in the outside the box realm with those ping results.
I’m not redirecting your internet traffic to the NSA or anything crazy like that, so no need for panic.
Given this is a local controller, have you been able to reach that when the rest of the devices can’t get to the internet? If so, I’m curious what the statuses of the Alta devices reported.
I didn’t try it recently but if memory serves me I couldn’t via the DDNS url, I could with the IP but I was frustrated and it was quite late so I won’t swear on it in court.
Thanks for all the help this far! I’ll keep the thread updated and reboot as needed. If you are; no need to sit around on my part.
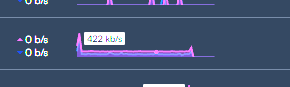
Can still access via DDNS address. Controller seems to flatline as well. pushing maybe 100kb/s like the other devices.
Did 1hr view to better show the Router, 2 APs and switch. Controller didnt let me do that range blanking out completely so I can only post the live data feed.
Sorry there a bit washed out. I have HDR enabled on this display.
Can you clarify where your QNAP is plugged into the network? I’m seeing sequential MAC addresses, but one is showing as plugged into the Route10 directly and the other shows it’s plugged into the S8.
This shouldn’t be a problem, but there are also no massive red flags, so I’m looking for those outside the box potential causes.
Sure; I have 2 coming from the NAS. 1 is via the S8, the management port of the NAS. The other is plugged into my 10G switch which comes in via 10G SFP also on the route10. That SFP 10G is the uplink to the entire 10G switch that hangs off of it. The actual data transfers happen over that 10G switch. So it appears twice.
My outbound connection lasted almost all of last night after a few frustrating days before dying today. After you left it dropped several times and I moved to WAN1 from WAN2.
I need to test it more; but I would like to see if its an issue with the transceiver or maybe the cable not seating properly (iv replaced it like twice for testing). Or maybe it just doesnt like the transceiver. I had an opnsense DEC750 that very much did not like suricata enabled using SFP.
In case it matters the following are what I generally run. They are simply tagged as “OEM” and while I’ve never really had compatibility issues with them I figured id throw it out there. I utilize 2 for the 10G LAN and WAN2.
I’m maxed out for today though. Thanks for all the time. I’ll check on this after some sleep.
No worries, I wasn’t really expecting a reply until tomorrow anyway.
If there is drop in communication it would be interesting to know what the link lights are doing for both of these links as well as if anything looks different in the way of link lights on the router.
Let’s start there depending on those results as well as if the issue persists, I think I’d like to try eliminating one of those QNAP links temporarily as a test if it’s not too much hassle.